
A preparação de um grande modelo de linguagem moderna (LLM), geralmente com parâmetros de aproximadamente 100B ou mais, envolve milhares de aceleradores e sobrecarga física, em execução por dias a meses. Nessa escala, o sucesso geralmente se resume a dois resultados principais:
- Velocidade: quão rápido o sistema de treinamento consome dados, geralmente medidos em benchmarks.
- Aprendizado: quanto progresso é alcançado por unidade de tempo, normalmente rastreado por perda versus relógio de parede.
Este artigo coloca intencionalmente entre colchetes o eixo aprendizagem/qualidade. Ele se concentra em questões sistêmicas: o que significa “rápido” em uma grande prescrição e como podemos medi-lo de forma ini-agnóstica?
A taxa de transferência bruta (sinais/seg) é necessária. No entanto, também é sensível ao contexto: com renderização de GPU, topologia de rede, local de armazenamento, modalidade de dados, comprimento de sequência, modelo arquitetônico e hiperparâmetros como tamanho de massa global.
Em outras palavras, o rendimento é um resultado, não uma medida normalizada de eficiência. Como a métrica restante orienta comparações entre pilhas e disciplinas de priorização, precisamos de uma lente de eficiência que expresse o progresso como uma fração da capacidade concluída, em vez de uma quantidade absoluta.
Espaço TNW City Coworking – onde o melhor trabalho é feito
Um espaço de trabalho para crescimento, colaboração e oportunidades infinitas de networking no coração da tecnologia.
Qual é a motivação por trás do bem: passar de “quantos sinais observamos por segundo?” tais como “que fração do potencial do sistema foi convertida no uso do progresso do treinamento?” O Google apresentou formalmente o ML Productivity Goodput como uma métrica de eficiência para sistemas de treinamento ponta a ponta e forneceu uma abordagem orientada por API para calcular fontes boas e ruins (perda de produtividade) em toda a pilha.
Do rendimento ao bom rendimento: por que a organização das coisas
É muito fácil postar e compartilhar, mas funde múltiplos fenômenos independentes;
- ConfiabilidadeO trabalho pode permanecer ativo ou é reiniciado com frequência?
- Recuperação e resiliência: quando ocorrem erros, quanto progresso é feito e com que rapidez ele se repete?
- Computação eficiente: Quando o trabalho está “em execução”, as GPUs estão realmente executando o modelo matemático com eficiência ou estão com pouca potência devido a travamentos e sobrecarga?
Uma predefinição pode parecer “rápida” (sinais altos/s enquanto estiver saudável) e ainda ser “lenta” na conclusão do relógio de parede se for interrompida com frequência, restaurada lentamente ou executada com baixa eficiência de computação.
É o valor da propriedade do corvo que obriga o estoque a contabilizar o tempo perdido e a tornar a perda atribuível a ele.
O que é um bom treinamento?
Treinamento é a fração da capacidade teórica de treinamento que é convertida em progresso útil de treinamento. Na verdade, o número está aqui (0,1)onde:
- 1,0 para ser para funcionar continuamente de forma frutíferasem que sejam contabilizadas quebras significativas de tempo perdido, recuperação, sobrecarga de pontos ou subutilização.
- 0,5 para ser cerca de metade do potencial é desperdiçadomuitas vezes de forma invisível, por um tempo, reinício, ou estábulos, ou sobrecarga.
O Google enfatiza que deve haver uma ação genuína: não apenas uma métrica de título, mas um detalhamento que explique onde o tempo é desperdiçado (má produção) e por quê.
Para contrair essa composição concreta para o LLM, é útil descrever uma pilha de treinamento em três frentes:
- Abaixo da camada (cluster, orquestração, tempos de execução, tratamento de falhas)
- Camada de estrutura (configuração de tempo de execução distribuída, pontos de verificação, gerenciamento de estado, inicialização)
- Camada de programa/modelo (paralelismo estratégico, núcleos, precisão, controle de lote/sequência; ou seja, como mapear eficientemente a matemática para o hardware)
Isto é semelhante à forma como as grandes organizações operam: diferentes partes têm diferentes camadas e os ganhos de eficiência exigem uma atribuição clara.
Camada 1: Abaixo do Goodput – “Com que frequência estamos realmente treinando?”
Abaixo está a disponibilidade do goodput: uma fração do tempo em que o trabalho está realmente em um estado de disciplina saudável, em vez de cair devido a falhas de infraestrutura ou atrasos de orquestração.
Uma definição operacional simples da janela de medição (W) é:
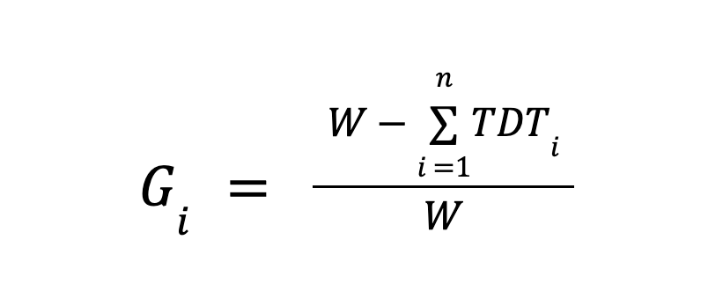
Onde:
- TDTeu* = Tempo de inatividade da carga de trabalho do cliente no i-ésimo distúrbio
- W = janela de tempo de medição Goodput (por exemplo, 24 horas)
- n = Número de pausas de treinamento na janela W *
Isso cuida das equipes abaixo: detecção de falhas, isolamento, remediação e latência de reinicialização. Clusters reais falham em escala de maneiras não triviais. A literatura sobre fiabilidade mostra que à medida que a dimensão do trabalho aumenta, o nível de vulnerabilidade do trabalho aumenta, e a recomendação deve ser concebida numa preocupação transversal e não “apenas armada”.
Camada 2: Framework goodput – “Quando falhamos, quanto lucro perdemos?”
A disponibilidade abaixo não é a história completa. Mesmo com uma reinicialização ao vivo, o progresso do treinamento pode ser perdido dependendo do estado e ser salvo e restaurado. É aqui que entra o quadro das coisas boas: mede a fração de tempo não perdida para verificar o capital e a recuperação de resíduos.
Acima da janela (W);

Esta equação salienta um ponto crítico que o rendimento apenas esconde: a repressão é um imposto contínuo, enquanto as falhas impõem penalidades discretas que muitas vezes incluem despesas gerais de reinício e desperdício de retorno.
Checkpointing não é “invencível e gratuito”.
Em uma grande prática distribuída, pode ser caracterizada por “E/S” e sobrecarga de coordenação. Raramente, porém, surge a ideia de aumentar o retorno da perda. A cláusula de marco “correto” é, portanto, um sistema de compensação clássico: grande (SST) sem inflação esperada (LST).
Camada 3: Modelo goodput – “Você está convertendo silício em matemática de forma eficaz?”
Mesmo o treinamento perfeitamente confiável e recuperável pode ser ineficaz se as GPUs forem usadas incorretamente. A métrica padrão aqui é a utilização de FLOPs do modelo (MFU), uma medida da eficiência com que o programa converte sua capacidade em FLOPs à medida que o modelo vai e volta.
Fórmula prática MFU:
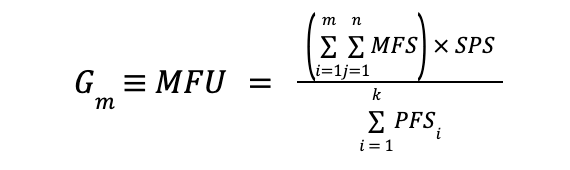
onde:
- MFS = FLOP do modelo calculado por parâmetro por índice por etapa
- m = número de parâmetros do modelo de aprendizagem
- n = Número de sinais de entrada
- SPS = passo observado por segundo
- PFSeu* = Pico teórico de FLOP por segundo na i-ésima GPU
- k = Número de GPUs participantes
MFU é amplamente utilizado para se referir à eficiência do treinamento e é frequentemente definido como “o pico observado no modelo calculado dividido pelo pico teórico do computador”. O MFU baixo geralmente não é um único “bug”, mas um efeito emergente:
- Cabeça de comunicação (redução total / coleta total) dominando as etapas de tempo
- Configuração de paralelismo ruim (incompatibilidades de TP/PP/DP/EP)
- Microlotes muito pequenos (preenchimento insuficiente do núcleo) ou gerenciamento inadequado de lotes/lotes
- Mas o otimizador de estado de memória e ativação/pressão
- Comunicação LINO suficiente com o computador
É aqui que as escolhas da “camada do programa” importam: DDP vs FSDP, escolhas TP/PP, paralelismo especializado para MoE, precisão (BF16/FP8), tamanho global do lote vs tamanho do microlote e programação detalhada de Recursos Coletivos.
Goodput de treinamento composto: uma métrica de eficiência em nível de pilha
Como temos três níveis de bens, podemos fazer uma meta para definir o objetivo do treinamento:
Treinamento Goodput (Gt) =Geu* Gmerda Geu
Onde:
- Geu* = Abaixo do Goodput
- Gmerda = Estrutura Goodput
- Geu = Modelo Goodput
Este número exclusivo (0,1)) é obviamente útil porque reconhece a pilha.
Como medir o bom investimento na prática
A Goodput é tão credível quanto a sua instrumentação. Uma pilha prática de medições geralmente inclui:
Medição 1. Defina a janela.
Use uma janela fixa (24h é comum para relatórios operacionais) e calcule (Geu*, Gmerda, Geu) na mesma janela para manter a atribuição constante.
2. Registre um “período de treinamento frutífero” expresso em palavras.
Limites de nível de log e transições de estado “ativas em formação”. As estruturas Goodput normalmente separam fértil horário de * durão categorias como quebras, reinicializações, sobrecarga e outros intervalos não produtivos. (Nuvens do Google)
3. Amarre o evento de cada falta de distração.
O trabalho de confiabilidade sugere medir as falhas com uma taxonomia e associá-las ao tempo de perda efetivo, o que é útil tanto para a contabilidade quanto para prever como as taxas de perda aumentam com o tamanho do trabalho.
4. Calcule o MFU do treinamento em estado estacionário.
Exclua aquecimento, avaliação, atrasos pontuais de longo prazo e tempo de recuperação ao avaliar o MFU, a menos que seu objetivo seja explicitamente “MFU misto”. O MFU é mais útil como cálculo de lente em estado estacionário.
conclusão
A prescrição do LLM para dimensionar problemas de sistemas fundamentalmente distribuídos gira em torno do grande problema matemático paralelo.
A taxa de transferência (sinais/seg) é o título necessário, mas a medida de eficiência não é estável entre pilhas ou ao longo do tempo.
Goodput fornece uma alternativa normalizada e decomponível: quantifica a fração da capacidade potencial de instalação que é transferida para o progresso real da instalação e atribui perdas a camadas que podem repará-las.
Assim como as academias de pesquisa e produção da empresa ou sublinhado, ambas as disciplinas de escalonamento têm tanto a ver com a redução do mal quanto com o aumento do rendimento máximo, e os ganhos da empresa vêm do tratamento da eficiência como uma pilha de propriedades, e não como uma única métrica.
Se você estiver construindo ou operando sistemas de ML em grande escala e começando a pensar em termos de qualidade no nível da pilha, em vez de apenas padrões por segundo, há um nível mais profundo de trabalho envolvido no local onde a infraestrutura, as estruturas e os modelos de design interagem.
Para debates contínuos sobre a eficiência do treinamento em larga escala, consi-ML de plataforma e infraestrutura de produtos impulsionada por IA, conecte-se com Anirban Roy sobre LinkedIn. Você também pode explorar o modelo de negociação de IA em LLMProxy.ai
Notas:
- Google Cloud: métricas Goodput como medida de produtividade de ML (Google Cloud)
- AWS: Treinamento sem checkpoint no Amazon SageMaker HyperPod (Amazon Web Services, Inc.)
- Kokolis et al.: Revisitando a confiabilidade em um cluster de pesquisa de aprendizado de máquina em grande escala (arXiv)




{kind=link}